Technical
19 Mar 2022
Multilingual Named Entity Recognition for Financial Transactions
Author
Chady Dimachkie
Engineer
Here at Ntropy we are working on providing the best service for financial transaction enrichment and that starts with being able to support as many possible transaction patterns as possible. To achieve this, we work towards Named Entity Recognition (NER) models that can generalize as much as possible and that are able to understand many languages at once, thus supporting many regions and markets. The main focus of this post is discussing the logistics of implementing multilingual solutions.
Named Entity Recognition Task
Named Entity Recognition (or NER), is a task where a model has to extract spans of entities from a given text, namely persons, organizations, locations, dates, etc if any is present at all.
In this post, we will be focusing on describing how we apply our methods on NER tasks for our specific domain of financial transactions.
Multilingual model vs many monolingual models
At first, we developed only monolingual models for use in production, that would each serve a particular country or region. Those would be trained on a specific language and would achieve very good accuracy since they have data from a similar language distribution.
The models we were using were based on a distilroberta (Similar to this model, but with slight architecture changes) transformer architecture which is light enough (6 layers), and in terms of memory, CPU, and GPU usage, they were perfect for very low latency and real-time queries.
So, why do we need multilingual models while many monolingual models would probably simplify things and work well (maybe even better) anyway?
While monolingual models may achieve excellent performance, when one looks at the practicality on a larger scale, we need to be able to handle transactions that can be seen in many different contexts, which is what our customers demand.
For example, imagine you’re living in the US but then you travel across Europe, you’ll still be using your US card to pay during your trip in Europe, but this means that your bank will have to process a foreign transaction which most likely won’t even be in English. And this is a very basic consumer usage.
Now, imagine even more complex behaviors and usages like businesses working internationally and estimating accurate cash flows, bookkeeping, etc.
Of course, one can argue that it’s possible to redirect each transaction based on the currency to correct the selection of the appropriate model. To this, we’ll answer that it’s not always an accurate method since one can use different currencies in different countries which will then get converted into the local currency automatically.
Or, one can say that we could have a language detection model (Fig. 1) that redirects to the correct model, but still, even here, there are many cases where this does not stand:
- Countries that share a language but have a very different banking system
- Just the fact that the detection model itself is inaccurate will trigger lots of false positives thus targeting the wrong language models
However, that being said, a language detection model can still be useful. We have built one already (with a precision in the high 0.90s), fine-tuned on transaction data, and we are currently using it internally for warnings that we can send to customers.
Finally, translation into a target language we already support is possible and is an approach we’ve also tried, but we discovered that it doesn’t work well since transactions in one country are often extremely different from transactions in another, hence the translated source distribution will differ from the target language distribution, meaning the models will often fail.
One might have actually already seen translation methods being used in different settings (like actual natural language) and they can definitely work well there. However, in domains where creating a parallel corpus with close to 1:1 translations is hard to accomplish, these methods do not shine. The issue we are trying to describe might be similar to translating region-specific expressions to a different language/region, there it is often impossible to map an expression to another one as you’re trying to compress context you don’t have, cultural bias, and other things into a target language that just doesn’t have the same prior.
Developing a multilingual model
Many ideas and consequent experiments were run out in order to achieve a very good multilingual model that can rival the individual monolingual models in terms of accuracy scores.
To better define our goal and expectations, we need to describe some of the settings of this project.
These include:
- How many languages do we want to cover and which languages?
- What training strategies could be used?
- How do we measure success and performance against the monolingual models?
Languages
The definition of the term “multilingual” implies at least 2 languages. Here, at Ntropy, we believe that taking small steps and establishing small goals towards success is key, especially when we don’t know how difficult a problem truly is. Hence, the first iteration of our experiments consisted of using 2 languages. However, to truly show the power of this technique and strengthen our theory, we also expanded to 3 languages. Furthermore, naturally, the difficulty of the task increases as the number of languages increases.
A natural question that follows up here is what languages to base our experiments on? Of course, we are bound to choose one of the languages predominant from our customers’ needs.
The top ones are (in order):
- English (US, UK, Australian markets among others)
- Portuguese (Brazil, Portugal markets)
- Spanish (Mexican market)
- French (European market)
- German (European market)
- Dutch (European market)
However, many more factors come into play here:
- How different the distribution of transaction data patterns is between languages?
- How different the languages are in terms of natural language?
- Labeling solutions used for each language
- The existence of pre-trained NER models that can support all of these languages
We have reached a conclusion that for a prototype, we shall focus on romance languages — Spanish, Portuguese, and French. The motivation for this is that we might expect similar embeddings and the syntax might be more comparable within these languages’ space. Moreover, statistical analysis tells us that the overall distribution of the English data is much different compared to all the other languages. However, later on, we will mention experiments conducted outside of these 3 languages — trying to integrate English as well and trying to construct multilingual models between English and German.
Training strategies
We have brainstormed many ideas that could have potentially worked for this project:
- Training all languages at the same time
- Training each language separately
- Cycling through languages when training
- Smooth cycling through languages via translation
- Training on majority class language and fine-tuning on minority/majority languages
- Testing one/few-shot capabilities to gather information on the similarities and differences between languages
- And even more that you’ll find in the “Further research and possible next steps” section!
All languages at the same time
This is a classic way of approaching the problem. It consists of merging the training, validation, and test datasets together of all languages and training afterward as a normal NER classification problem.
This approach works to a certain extent but doesn’t capture all the fine details of every language and often loses many accuracy points compared to several monolingual models on each individual learned language. Let’s see how and why!
This approach is very simple but has a few issues, first, the model might need a good multilingual pre-training otherwise it’ll be completely confused with all the different distributions during training. Basically, the gradient will be trying to go towards many different parts of the loss landscape and the model will need to adapt to lots of different distributions at the same time, meaning the training will be noisy and will need many epochs and even a more adapted loss to such noise.
On top of this, it is hard to tune the hyperparameters since you’re sharing them for all languages.
Each language separately
This approach is different in that it takes each language and does a separate training on each of them, with their hyperparameters since some languages could need more epochs, different learning rates, etc.
The “gist of it” is that the model is going to be very good at the language it trained on last and still be good enough on the other ones it trained on. This happens because the model is being specialized every time on a new language and this means it will start forgetting about the previous languages it learned and used to perform well on!
This is a huge issue because it forces a big compromise on which languages we want the model to be best at!
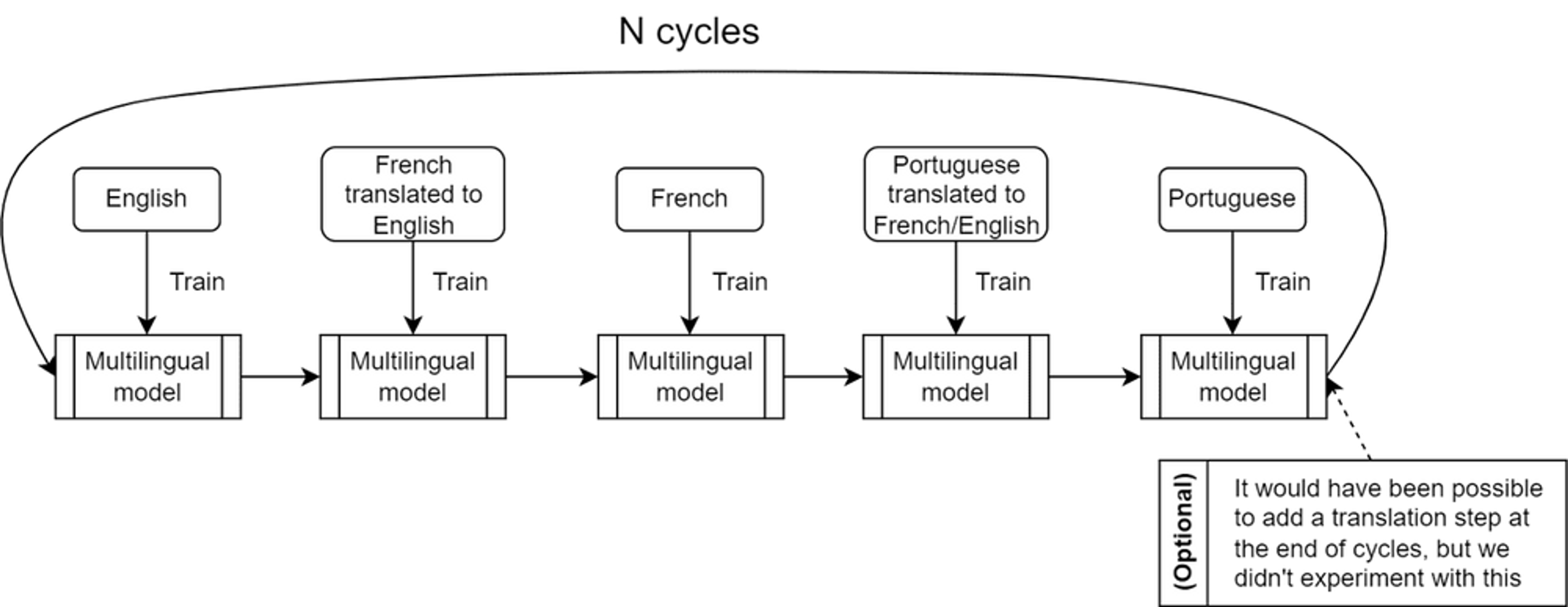
Cycle through languages
One of our solutions that seemed promising was to basically go further on the above method and “cycle” through the languages by basically iterating through the process N times and even allowing different hyperparameters for the same language based on the cycle step.
Why would this work better?
The intuition is that, similarly to training for several epochs, even if you learn some samples well but then shift to a different distribution than what you’ve seen in previous batches, then the model will need to go to a very different region in the loss landspace to accommodate for those new samples and learn them well which might make you forget what you saw previously.
This means that several language cycles just enable your model to remember and relearn the previous languages with its newly acquired knowledge of other languages, similarly to epochs when you classically train a model.
We’ve experienced that this method provides the best performance so far to train multiple languages that can’t be learned through the creation of a parallel corpus.
In practice, even if this works well, this method introduces a new hyperparameter that is the number of cycles N, which is one more hyperparameter to tweak, and not only this but you also need to tweak the hyperparameters per language within a cycle which might increase iteration time.
However, note that, even if this method is not that different or much more complex than the previously described one, it comes in practice with many more issues!
One cannot just decide to apply a loop over the previous method and call it a day. There are scheduling problems for smooth training and logistics problems concerning the test and validation sets.
To describe these even further, careful scheduling of learning rate and early stopping are required to still prevent the recency bias that’s present as with the previously described method. We have used LR decay even cross-langs with respect to the number of cycles for a smooth training session. Forgetting remains also a big issue. Moreover, having very good held-out test sets is especially important in this context compared to a normal training session on a single language. This is because, with cycle training, there is a higher risk of overfitting even with smaller learning rates than in monolingual setups (due to training on each individual language multiple times and not knowing the landscape of the loss function). Hence, we absolutely need to be sure that the test set is well constructed, slightly out of distribution compared to the validation and train set.
Fortunately, we have developed a simplified pipeline to make this work nicely. In practice, we define each step in the pipeline as a Run and those steps will get executed while using the best previously trained model.
Here’s an example of training French and then training on Portuguese:
As can be seen, we just define the relevant parameters for each run, and then the pipeline takes care of everything. Here the pipeline will be run for exactly 3 cycles, which means that this will be repeated exactly 3 times. But if more precise handling of any hyperparameter is needed, for example, decaying the LR each cycle, then it can be done very easily in a loop!
On top of this, it is possible to apply testing of the current model on any dataset, we do this to test the performance of the current model on past/future languages. We’ve also made it easy to just apply hyperparameter tuning to each cycle by only changing one parameter.
This approach worked best and it is the one ultimately implemented in our stack.
Smooth cycling through languages via translation
Another method we developed that relies on the previous approaches too is smooth cycling via translation.
Basically, the cycle method is applied but before each language training stage, translation to the previously (or all previously) learned language(s) will be applied to the new language.
The idea here was that if the model is struggling to get good performance on a new language since the distribution is too different from the previous language, then translation could offer a simpler way to reach a minimum that would solve the new patterns from this new distribution but using parts of the previously learned language’s distribution.
The translation was done so that there would be a balance between the 2 language distributions by only translating non-entity words and occasionally replacing entity words with location/language specific entities.
This approach, albeit promising, didn’t work that well. Here are some possible explanations to why this was happening:
- The “smoothed” transactions distribution is actually not at all in-between the source and target languages thus only adding noise
- The poor results of the pre-trained translation models we used were shifting the distribution too much, thus making the final smoothed transaction too noisy
- We did not try training translation models as we can’t easily create a parallel corpus since all the languages have such different distributions of patterns for even the same type of transactions
However, it is very possible that this method works well in the context of classic natural language datasets since translation models are much better in those cases, parallel corpus creation is much easier and translations will indeed be within the target language distribution.
How do we measure success and performance?
For performance metrics, we use f1 scores (usually used for NER tasks in general). We have f1 scores entity-specific (organization, location, etc.) and an overall f1 score (which is mainly the one we optimize for).
To declare success in this project, we need to compare the overall f1 score for each language against the monolingual f1 score (for each language).
We declare success in an experiment if and only if one of the following three bullet points are satisfied:
- The overall f1 on the multilingual model is better than monolingual strength in every language.
- The overall f1 on the multilingual model is the same (+/- epsilon) as the monolingual strength on every language.
- The overall f1 on the multilingual model is within the noise limits (+/- 1.4 points) of the monolingual strength of every language.
For clarification, the monolingual strength is the best overall f1 we can obtain by training in a single-language fashion.
Experiments — results in practice
Experiments in 2 languages (Portuguese and Spanish). We can see the results in table 1.
We say that our training has converged if and only if, for every language l, the validation score when training on the language l remains the same (+/- epsilon adjusted) as the validation score on language l when testing on it after training on each of the other languages conjugates. In other words, if the validation score drops when switching to another language, that’s a bad sign that the model is not stable.
Monolingual strengths:
Observe that this experiment was successful, the results for the convergent model are the same as monolingual ones. Note that for this, we have used 4 cycles, decaying LR + early stopping.
Moreover, what is interesting is that we can actually obtain a meaningful boost in the score (as we can see for the non-convergent version — 2 pts higher on Spanish) with the cost of other languages scores (about 5 on Portuguese). This means that there is meaningful information in the Portuguese dataset that also helped Spanish. Even though that model is not stable and severe forgetting happens, it is possible that with better scheduling of hyper-parameters, we can get it to work and keep the higher scores (as we will see in a moment).
Integrating French now as the third language is expected to be challenging, as the distribution of the data expects to shift a lot.
The results are presented in Table 2. Observe that we needed more cycles this time for a meaningful output. After 11 cycles we get the same results as the monolingual strengths (which is a big milestone), however, with some hyperparameters optimization and LR decay over the number of cycles we actually got better results for 1 language (and the same scores for the others) which is an even bigger milestone.
This may be proof that the embeddings from a language can help the other languages. We are confident the model did not overfit due to multiple training runs on the same sets as we have clear delimitation between train/valid and held-out test sets which are especially good on French.
An interesting find and consequence are that for some specific entities, we get higher scores. For example, the monolingual strength for Portuguese Person is 0.722, while the Portuguese person score for the last model shown in table 2 is 0.744 (decent improvement), but it does lose a little bit on the Date score. This does make sense as people can travel the world and hence appear over multiple regions with the same name.
A cool graph shows the descendants of each language score of the multilingual model to the monolingual strength.
The training runs were conducted using a multi-GPU machine (4 Nvidia Tesla V100) and took about 8 hours. The base pre-trained model is represented by an XLM-R transformer language model pre-trained on general multilingual NER tasks.
Some details (like the number of training samples) were omitted to protect the privacy of our internal systems and our customer’s data. The order of magnitude is at least 1⁰³, depending on the language.
Even though the results look great, we do have to keep in mind some technicalities:
Data is not perfect. It does contain mistakes and we may be using different mass labeling solutions for different languages. This means that if there is a conflict/contradiction over popular patterns of entities, we will just continue to lose points at least on one side. Example: pattern xx/yy where xx and yy are 2 digit numbers with xx<=yy. If someone labels them as Date for Portuguese transactions and another labeling team labels it as Other, then the model would probably just choose the majority class (if it doesn’t overfit).
- Would it be possible that the multilingual model has similar performance as monolingual models by internally fitting a language detection model that’ll redirect to other internal monolingual models, thus being a proxy to our previous pipeline?
Is there actually synergy and knowledge sharing between the distributions of the languages? Here, we cannot really answer the question fully. There are hints that one language can help the other, however, the bias of the multilingual model can be low enough that a phenomenon described in the query can happen. The main question is, is it really a bad thing that the resulting model could have an internal language detection that may be more robust to a separate one? It might not be
- How scalable is this approach?
We are able to get decent performance in 3 languages, but it remains harder and harder to tweak as more languages are added. What if we were to include an order of magnitude higher number of languages? Although we don’t have the need at the moment to develop models for more than 10 markets, it is definitely an issue to look out for in the future.
- How costly is the maintenance of such a big model?
If we get new data for just one language, do we need to retrain it all? In theory no, one of the biggest strengths that made transformers so popular and sophisticated is transfer learning. We believe that with careful sample weight adjustments and delicate fine-tuning, maintenance can be routine.
Integrating English or German alongside Portuguese+Spanish has been tried.
However, here, the best results were getting the scores within the noise limits of the monolingual models (but on the lower side). This is still satisfactory, however, the experiments clearly showed a more challenging task. Hence, the family of the languages might matter a lot when building a multilingual language model. It might also mean that the data of English or German contains so many different patterns than the Portuguese + Spanish that it’s probably a more delicate task to make it work. This will remain for further research on our side.
Further research and possible next steps
Of course, we are not stopping there, we have many more ideas coming!
Among those, exploring model knowledge distillation is a big one:
- Distillation of several monolingual teacher models into a multilingual student model
- Applying the cycles method on the distillation of teacher models is another interesting idea that seems promising
There is also ongoing internal work on noise-robust, retrieval augmented, and few-shot efficient models that will definitely be very useful in the context of having an efficient multilingual model.
Stay tuned, more posts are coming!

