Company
28 Jun 2023
5 Pitfalls of Building Transaction Enrichment Solutions In-House
Author
Michael Jenkins
Product Marketing Lead
In this article, we will discuss the transaction data enrichment process and delve into the pitfalls of building in-house capabilities and highlight how Ntropy, the leading provider of financial data standardization and enrichment APIs, offers comprehensive solutions to overcome these hurdles.
Transaction enrichment and categorization
Financial institutions, particularly banks, have always had access to their customers' financial transaction data but open banking and data aggregator services now facilitate other companies to also get access to such data. This wide availability of transaction data has enabled its application in innovative use cases, such as underwriting, more frequently than ever before.
A financial transaction can contain such metadata as merchant details, date, amount, currency code, description, MCC code, pending status and other fields. It can also have information about a third-party payment processor if one is involved. However, with many different entities involved in a transaction and different legacy software of the entities, transaction data is very messy and difficult to understand for humans and language models.
Transaction enrichment and categorization is a clear need for anyone building financial products or services, whether those are banks, fintechs or software companies embedding financial products.
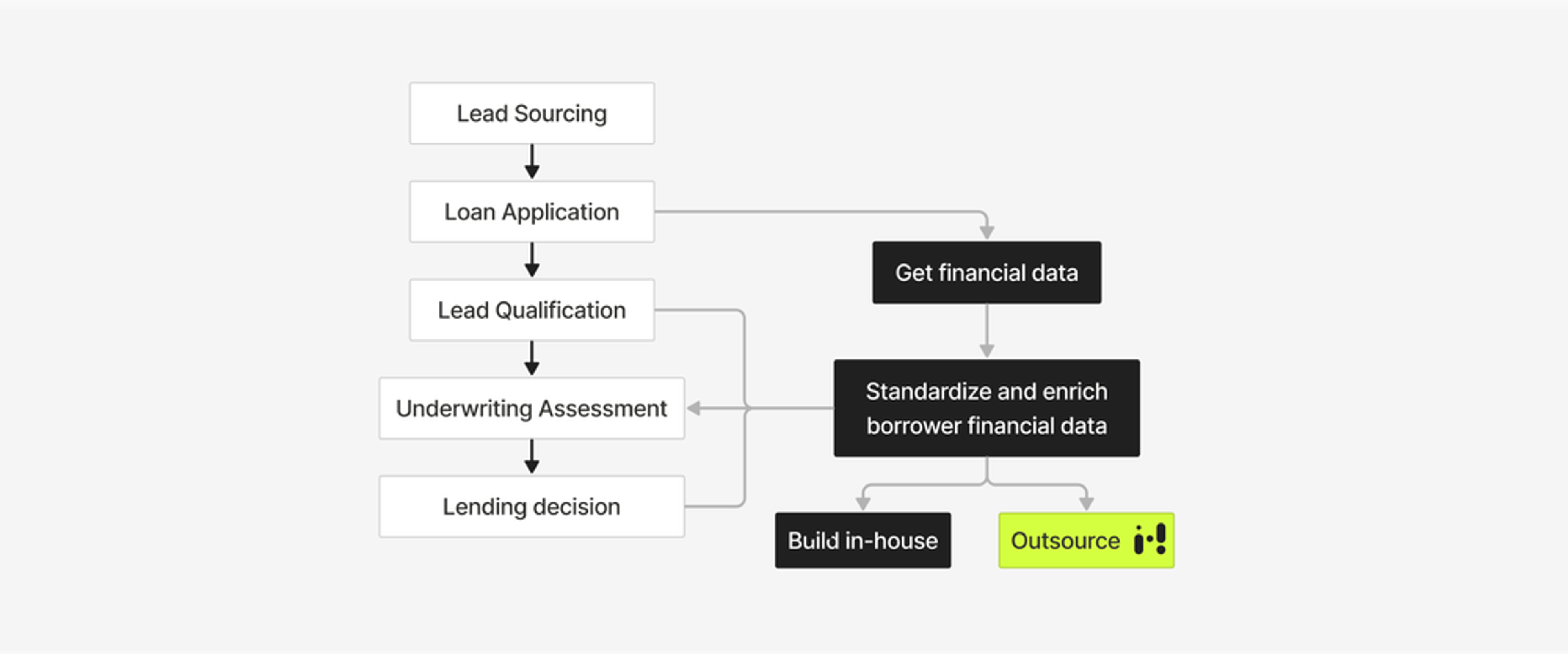
Having the payment data available is the first step, making sense of and actually using it in the underwriting process is next. Transaction enrichment and categorization can help with lead qualification, shortens the time for credit risk assessment and ensures better lending decisions and overall customer satisfaction.
The interpretation of a transaction differs for the sender and the recipient, making it challenging to assign a unified meaning. For example, a transaction like a bill payment for a corporate dinner party holds different implications for the restaurant (sales) and the organizing business (employee expense). Likewise, a payment made to AWS can be seen as cloud computing spend for a startup and revenue for Amazon.
This process of reviewing and analyzing the financial data can be a time and human resource-consuming task, given the complexity and messiness of the raw data. This is why underwriting teams are increasingly using automation systems for transactions data cleaning, enrichment, and categorization, according to their underwriting processes and needs.
Examples of enriched transaction data
Here are a few examples of messy transaction descriptions:
And here's what this raw payment data can be converted into with the help of enrichment models having merchant details such as name, logo, website, MCC and other metadata added:
In order to interpret and automatically categorize transactions as in the example shown above, businesses can decide to either build an in-house model or outsource the job to experts.
The decision to build an in-house machine learning (ML) model for payment data enrichment may seem tempting at first, but it often leads to a multitude of challenges and complexities. It is complicated and time-consuming even for humans to interpret and correctly piece together information around a transaction. Parsing it programmatically is even harder.
Challenges in developing an in-house transaction data enrichment model
1. Narrow and insufficient data
One of the biggest challenges in developing an in-house ML model is having a limited and narrow dataset. To start building a transaction enrichment model in-house, a robust merchant database with tens of millions of entries and a diverse transaction dataset of 100-200 million transactions would be necessary. On the other hand, more data does not always mean equally better results. The accuracy and consistency of financial data play a pivotal role in business underwriting and risk assessment. To be accurate a model needs to learn from diverse data across multiple sources, geographies, and use cases to process account information from a wide range of transaction sources such as open banking data, debit and credit card transactions, and user-provided bank statements.
Unfortunately, in-house datasets for business underwriting often lack the necessary diversity and breadth to train a robust model that can effectively generalize across different sources, geographies, and use cases. Apart from accessing diverse data sources, it is also important to carefully select and balance training methods to achieve high-quality transaction enrichment. These methods may include human data labeling and quality assurance, utilizing and validating merchant databases, as well as leveraging search engine result pages. Additionally, benchmarking data plays a crucial role in measuring the accuracy of transaction enrichment performance.
The Ntropy solution
At Ntropy, we differentiate ourselves from other industry players by leveraging diverse sources of financial data and employing a combination of methods for categorization. Our language models are built on a wide range of financial data sources, including bank transactions, accounting data, payments data, and consumer and business data from different countries. In addition to these sources, we utilize methods such as human data labeling, merchant datasets, SERP pages, and benchmarking data to enhance the categorization of financial data. This exposure ensures that our models are adept at understanding and enriching financial transactions with accuracy and consistency that is superior to the players in the market.
2. Overcoming Merchant Enrichment "Long-Tail Problem"
Accurately categorizing transactions is crucial for complex applications like underwriting, credit scoring, or fraud detection. A single misclassified transaction can have a significant impact on a business, potentially leading to financial loss.
Accurately identifying and categorizing small and lesser-known merchants poses a significant challenge in data enrichment for financial institutions. While it is relatively straightforward to recognize popular brands, they represent only a small fraction of all merchants. In the USA, the long tail problem arises. Based on Ntropy data from existing transactions, the top 500 most visited merchants cover half of all transactions, the remaining 50% of transactions are distributed among millions of smaller merchants, making their correct classification difficult.
Therefore, developing a solution that addresses the top ~500 merchants can be a relatively quick and easy task. However, training a model to accurately understand 75% or higher of all transactions can take years to achieve.
To address this challenge, businesses often rely on purchasing static merchant databases of “real data” to train their in-house models. However, in a rapidly evolving landscape with millions of active businesses and thousands of new ones emerging daily, no off-the-shelf database can keep up with the long tail. Building an in-house model, therefore, requires significant human labeling along with leveraging external data sources or using ML algorithms for training of models.
In the light of these challenges, utilizing a provider specializing in financial data enrichment often proves to be the most cost and time-effective solution that allows to leverage the expertise and infrastructure of a specialized provider who is solving the long-tail problem not just for one but many high transaction volume customers.
The Ntropy solution
Ntropy's model is trained on diverse datasets, continuously growing through its global reach, provides unparalleled coverage, ensuring that even the most obscure merchants can be identified and enriched with precise information. Companies can leverage this extensive coverage to enhance their understanding of consumer and business behavior and make informed decisions based on comprehensive merchant information without missing important insights from long-tail merchant information.
3. Cost and Speed to Market with Financial Data Enrichment
In the fast-paced business landscape, time is of the essence. Developing an in-house ML model for transaction data enrichment can be time, money and human resource-consuming. It involves various stages, requiring extensive research, payment data collection, model training, refinement and can take over 6 months and several $100,000’s to build human labeling, engineering, computing and cloud infrastructure to get to a passable level of accuracy. This intricate process can impede a company's ability to quickly adapt to market demands, and will reflect on its bottom line. It will also divert focus from their core product offering that is driving revenue resulting in lost opportunities and sunk costs.
Moreover, this level of initial time and money investments can often restrict smaller businesses from harnessing the power of data enrichment all together.
The Ntropy solution
Ntropy eliminates high budget barriers by offering an accessible solution with no upfront costs. Businesses can start leveraging our API within minutes without the financial burden associated with building an in-house solution. Besides, Ntropy's API enables seamless integration of transactional data enrichment into existing systems. This accessibility and agility accelerate the time-to-market for companies products or services and gains a competitive edge without straining their budgets. You can read more about how our customer Wayflyer quickly scaled their business internationally using our multi-geo and multilingual transaction enrichment capabilities.
4. Integration of New Data Sources
Data is constantly becoming more open and accessible and financial data is no different. Over the past fifteen years, we have seen a proliferation of APIs capable of providing access to bank and financial institutions data, card and payment, accounting, credit bureau, identity data, commerce, advertising and payroll data. With new data sources emerging regularly, adapting in-house models to accommodate these new sources can be a daunting task.
The Ntropy solution
Ntropy, as a specialized provider, remains at the forefront of the fintech data industry. We continually train our model by integrating new data sources into our API, ensuring that our clients have access to the most relevant and accurate information. This effortless integration saves companies the time and resources required to manage and integrate data from emerging sources independently. As we sign more customers, the collective data network we have becomes more robust and comprehensive. This creates a virtuous cycle where the data network effects amplify the insights and value that all participants can derive from the shared data.
5. Talent Acquisition: Quality and Availability
Talent acquisition and quality is another major pitfall of building an in-house machine learning (ML) model for transactional data enrichment. To establish one, businesses would need substantial internal resources, including dedicated data and QA teams, ML and engineering teams, as well as a human labeling team.
It can be a daunting, time-consuming and headhunting-intensive task to find professionals who possess the necessary expertise in this specialized field, understand the intricacies of in-house model building and can tackle the various complexities and solve the problems that arise during model development. From understanding different data sources and their nuances to addressing issues related to data quality, biases, and accuracy, a robust in-house team must possess a diverse skill set and have the ability to continuously improve and refine the model.
The Ntropy solution
Fortunately, by outsourcing the transaction data enrichment process, businesses can alleviate the burden of talent acquisition and quality. Sometimes even with the top talent team, companies can face challenges given the fact that the technology is evolving quickly. Ntropy has assembled a team of highly skilled professionals that combine an understanding of the fintech industry and deep technical expertise in machine learning to create a team with a proven track record of delivering exceptional results. At Ntropy, our team structure is composed of approximately 75% technical experts and 25% non-technical professionals. We have dedicated human labeling and QA teams, as well as specialized ML and engineering teams.
Conclusion
In the realm of transaction categorization and financial data enrichment, adopting in-house solutions may often prove to be impractical and inefficient, considering the comprehensive scope, extensive coverage, and easy availability of ready-to-use solutions. A fitting analogy would be comparing the utilization of cloud services to establishing your own data centers. Building and managing data centers necessitates significant resources, encompassing infrastructure, maintenance, and specialized staff. Conversely, cloud solutions deliver the same services more swiftly and cost-effectively, benefiting millions of businesses worldwide. Thus, ready-made solutions in transaction categorization bear similar advantages, advocating for their broader acceptance and use.
In the realm of transaction data enrichment, Ntropy stands out as the optimal choice for businesses seeking accurate and standardized financial data. By outsourcing to Ntropy's, companies can leverage the advantages of robust training data, overcome the long-tail problem, accelerate speed to market, enhance data quality and integrity, integrate new data sources effortlessly, achieve cost-effective accessibility, as well as free up valuable internal resources that would otherwise be spent on building and maintaining an in-house model. This means you can redirect your efforts toward core business activities and leave the complexities of data enrichment to the experts.
As the fintech industry continues to evolve, relying on Ntropy's expertise ensures that businesses stay ahead, and make informed decisions.
Unlock the Power of Your Data Enrichment: Upscale with Ntropy
Whether you're a fintech startup or an established financial institution, Ntropy's API integration empowers you to supercharge your data analysis, decision-making, and strategies.
You can experience the magic of our transaction data enrichment and categorization firsthand on our homepage.
Ntropy offers a seamless integration with our API, making it easy for you to enhance and analyze your financial data. Getting started is quick and effortless, taking less than 10 minutes. Simply generate an API key through our user-friendly self-serve dashboard, and unlock the full potential of your data.
Our API documentation delivers an exhaustive guide to the integration process, promising a streamlined and frictionless activation that your engineer can implement in less time than a coffee break.

