Technical
02 Dec 2022
Herding Entities
Author
Marcin Zieminski
ML
Introduction
Ntropy works in the business of “transaction intelligence”. At its core, lies enrichment of financial transactions. With the Ntropy SDK, this can be done in just a few lines of Python code.
from ntropy_sdk import SDK import pandas as pd txs_df = pd.read_csv("transactions.csv") sdk = SDK("API_KEY") enriched_txs = sdk.add_transactions(txs_df)
So just by reading your transactions and quickly passing them through our API you can extract key information and build higher level insights in a structured form.
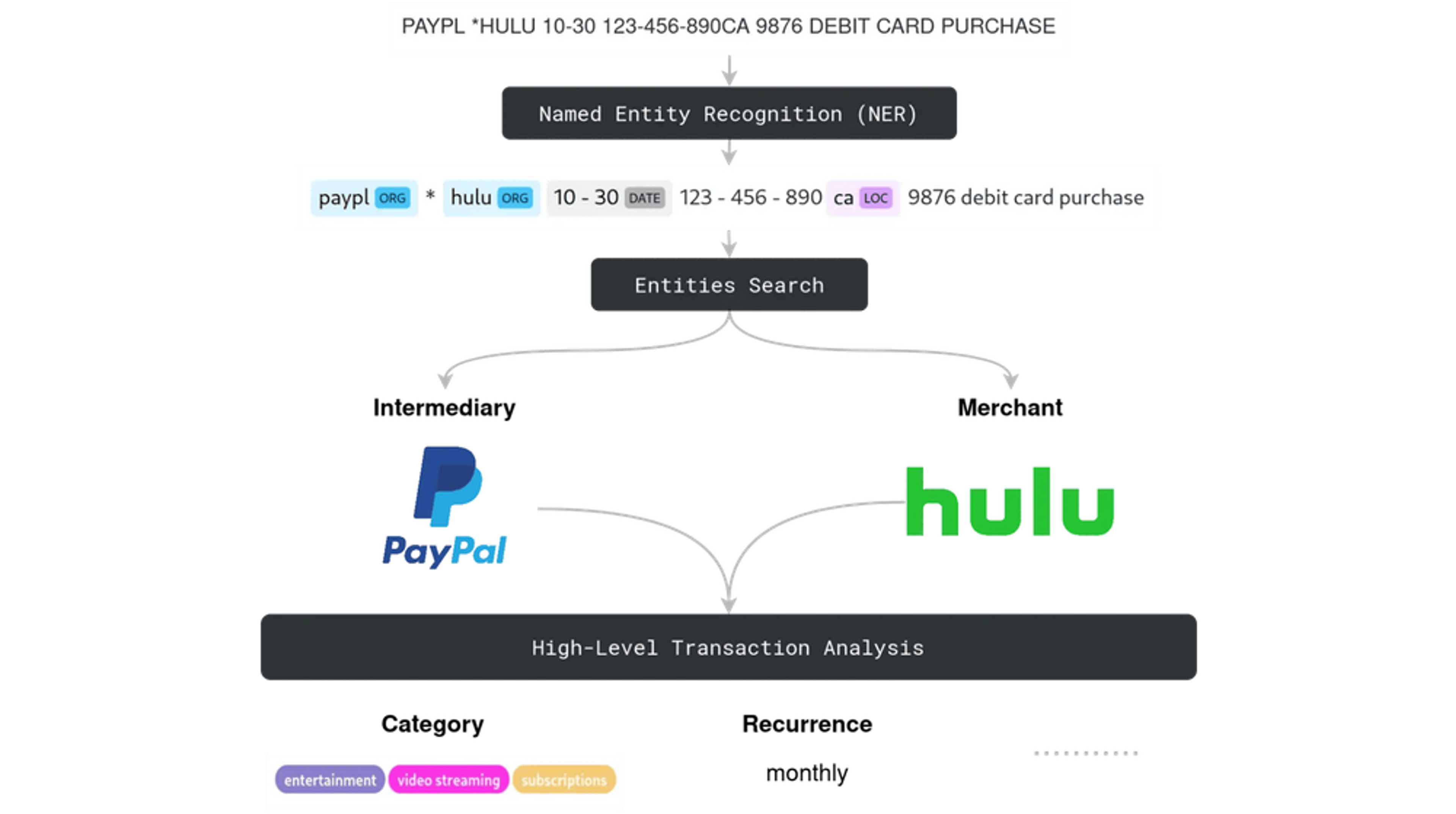
Consider the above example, where an innocently looking transaction text is transformed into a richer and more abstract representation:
- merchant is resolved and returned, including its website and logo;
- location of the transaction is inferred from the detected store id;
- transaction is assigned a category;
- given the nature of transaction and a wider context of particular account holder’s history we can say if it falls into a recurring pattern;
- and more…
At first glance it seems deceptively simple, especially with that arrow in the middle being so unassuming. But in fact, the flow of our algorithm is an involved and surprisingly delicate process, which, for the sake of simplicity, could be broken into the three key steps:
- Named Entity Recognition (NER) — as the name suggests recognizes the main entities and their kinds in the raw description string;
- Entity Search — determines key parties of the transaction, such as merchant or intermediary;
- High-Level Transaction Analysis — in reality is a series of multiple, sometimes independent steps, which build upon the information extracted earlier.
The enrichment flow diagram (enrichment is one of our favorite words) tries to capture the aforementioned steps using an exemplary transaction with two ORGanizations detected. This blog piece is devoted to the middle part of the algorithm, and with each section of this article we’ll be zooming into it to see how one can implement an entity search system for financial transactions. Resolved entities are not only a precondition to the subsequent steps of our algorithm, but are also one of the pieces of information we return directly from the API. Thus, we have to tread with caution when designing such a system.
“Herding Entities”
Admittedly, entity is an excessively overloaded term with a wide variety of meanings depending on the context. So let’s start by narrowing its scope and see what entities are for us, and why they are so unruly…
First, we hasten to mention that we don’t have any better definition than the one based on examples and some common sense. Entities in the world of transactions have to describe the essence of the parties involved, and do so in the most effective way. So entities may be:
- organizations — Amazon
- government institutions — IRS
- concrete services — YouTube TV or Apple Music
- physical places — Taco Bell restaurant at 8th Avenue
- freelancers, politicians receiving donations
- …
What is more, entities are not some unrelated objects hanging in the void. In each transaction they have their own particular roles:
- merchant
- intermediary- payment processor — PayPal- delivery platform — DoorDash.
Somewhere far away, in a better world than ours, clean and detailed entity information is attached to every transaction when it is brought to existence. But here due to lack of shared established standards and well-defined protocols we have to rely on a crude and minimalistic common language of transactions:
- plaintext description;
- amount;
- basic metadata — currency, country.
Fortunately this makes our work more challenging and meaningful.
To make matters worse, transaction descriptions are a universe of their own. They frequently contain idiosyncratic abbreviations for some organizations, e.g. “pp” often stands for PayPal. An entity, let’s say a company with a name Some Great Company Inc. and a website www.sg_company.com may appear in transactions in a plethora of degenerate forms:
- “somegrt cmpny”
- “some-grea-comp”
- “sgc”
- “www. sg comp . com /bill”
- “uniqu great prodct” — only provided by Some Great Company Inc.
- …
That degree of obscurity engenders ambiguity — is “ck” Calvin Klein or Circle K? What is more, we lose lots of valuable information. For instance, an address which could be helpful in determining the merchant like “840 8th Ave, New York, NY 10019, USA” , becomes severely mutilated as “ny, us”.
Having defined the issue, we can start outlining our attempt at the “herding entities” problem.
Entities Search Algorithm
Entities search starts where NER ends. Upon receiving token classification we focus on the list of detected organizations [ORG₁, …, ORGₖ] and location LOC, which we all treat as entity candidates. Note that the location string alone in some cases may point us to the underlying real world entity (the entire description may be the location of some restaurant).
Ideally, we would already jump straight to search engines, but we don’t have all the time and resources in the world. A single candidate search job may eat up some of precious request execution time, and incur a non-negligible dollar cost. Therefore, before we actually begin, we estimate resource budgets bᵢ for each candidate (ORGᵢ, LOC). The goal of this stage is to define resource constraints, which may depend on the execution mode, “real-time” vs. “batch” (which differ in allowed latency), and on the list of the query candidates themselves. So we try to find the answers to the questions like:
- How much time can be spent in total on each candidate?
- How many search results can we process?
- Should the requests to external services be limited only to previously cached results?
- How many queries to a given search engine can we afford?
Please recognize that at this point we have to act fast, and for this reason we leverage our domain knowledge, which is embodied by the carefully crafted Domain Metadata database. You can think of it as a rather small store of quickly accessible and simple patterns to guide the whole enrichment process. It does not cover most of the possible scenarios, but helps us navigate in some peculiar but important situations. For budget estimation we look up the patterns matching our candidates to see that e.g.:
- “funny_pattern” is always the entity with the website www.funny.pattern.com — no need to search at all;
- “some_merchant_pattern” usually corresponds to the merchant — requires more resources.
Now that we have the final entity candidate triplets, (ORGᵢ, LOC, bᵢ), we run parallel search jobs, each of which should yield a list of resolved and accepted entities with accompanying confidence scores. These are then passed as input to the last step which is responsible for solution selection and role classification. The outcome of it is often a short list of unique, detailed entities together with the corresponding transaction roles. However, sometimes it occurs that results are not satisfactory (maybe the budget estimation part was too optimistic), but we still have some spare resources. Then we re-estimate the budgets and run the searches again using some freshly acquired knowledge.
Now, we should dive a little deeper into the single entity search procedure of our algorithm.
Single Entity Search
Yet again we can depict another sub-routine as a sequence of three steps (let’s see if this property holds for the rest of this blog post).
- Search Engines — yield results in the form of triplets of the applied query, resulting entity, and engine-specific metadata;
- Re-ranking, Resolution, Selection- we join equivalent entities across results into groups- each group is assigned a confidence score- low-performing groups are discarded;
- Entity Enrichment, Representation Tuning — equivalent entities are merged and enriched with more information to give shape to the final list of entities to be returned.
Search Job Phase 1: Search Engines
As we continue zooming in, we discern that given an entity candidate we may construct multiple queries for each of the s available search engines.
Every search engine has its own idiosyncrasies making it respond better to certain kinds of query formulations. Sometimes it makes sense to build queries like “<ORG> in <LOC>”. The other times the search engine may suggest some auto-corrections to the query itself. This, on the other hand, may turn out to be destructive, so we may have to check two different versions as a consequence. In the end each request results in a small list of results (typically less than 10), which we model as:
- applied query — crucial for further analysis during re-ranking;
- entity — representation is search engine specific;
- metadata — search engine name, ranking within a particular request, anything that can be helpful later at assessing the quality of the match,
and then join together into a flat list [(q₁¹, e₁¹, m₁¹), …, (qₛᵏ, eₛᵏ, mₛᵏ)].
Web-Search Engines vs. Entity Search Engines
As you have just read, we use several search engines and you may ponder what these services are, or why we need more than one. In order to understand our reasoning let’s start by breaking them into two major categories: web-search and entity-search engines.
Web-Search Engines
Web-search engines are the kind of services that every internet user has to be familiar with. The notable examples are Google or Bing search. They have some useful characteristics, but at the same time bring in some serious pain points.
Their biggest advantage is that they are up-to-date with the world. Whenever there is a new company publishing their website, it cares about being indexed and appearing high in the search results. In other words, web-search results are positively correlated with financial data:
company is popular and gets indexed high -> people pay for its products -> we see it in our transactions -> we search for it -> we find it at the top of the page.
The search results are also arbitrarily fine-grained. We not only get main websites, but also the urls and descriptions for some concrete products or services (Amazon Prime, XBox Live), which is invaluable for deep understanding of transaction data. Another useful byproduct is that they also tend to be a window into other search engines or entity aggregators, which we can take advantage of. Not every freelancer or restaurant has a dedicated domain, but they are likely to be found through the results containing Yelp or Facebook pages.
Now let’s talk about some disadvantages. Web-search results come in an unstructured form making us implement a dedicated logic for entity info extraction, which is really a non-trivial task.
The results themselves are, as expected, quite unstable. Titles and snippets change over time and as such may stop us from finding the entities we used to be able to detect. In particular snippets frequently bring no real information and succinct information on the organization, like the last time we searched for “coinbase”:
https://www.coinbase.com Must verify ID to be eligible and complete quiz to earn. User may only earn once per quiz…
Another rather obvious problem is that they can get you virtually anything for almost any query, so our system must be robust at rejecting bad apples.
Entity-Search Engines
Entity-search engines stand somewhat in contrast to the web-search ones. Search results are served in a palpable manner, usually in the shape of clearly defined JSONs.
{ "name": "Company", "website": "website.company.com", "logo_url": "https://website.company.com/logo.png", "tags": ["tag1", "tag2"], "country": "Moon", ... }
More importantly we receive entities linked to existing organizations, not websites with baby name suggestions. Unfortunately this is also their curse, as they spit out pretty-looking entities, even when they should not. This makes it difficult to make up for their failures in an automated way.
The upper bound on the performance of the entity-search engines is the quality and the coverage of the underlying databases, which is often lacking and very much market-dependent. Moreover, because of their abstract and high-level contents we have very little chances for recognizing companies indirectly through the corresponding products or services.
Ensembles and Optimizations
In the light of the above arguments, we have no better choice than to build an ensemble of different search services mixing web and entity search kinds, and let them complement each other.
Unfortunately these services are notoriously slow and expensive. Because of that we built a two-level caching system. Firstly, each request is cached with semi-random TTL in our key-value database as:
key=(“<query>”, [params, …]) -> {REST result}.
Even if we are about to hit a self-imposed internal request timeout, we let all the search requests finish happily in the background, and fill in the cache for the future generations.
Still, we have to be fast and reliable. What do we do if we’re short on time and “query” is not cached? We fall back to “fuzzy caching”. The intuition is as follows. Imagine the query is “amazon market”. It is then likely that we have searched for “amazon marketplace” or something similar some time in the past, and the results should remain pertinent. Though, one has to take special care and treat the cached values with a greater dose of suspicion.
Building Our Own Entity Search Engine
The truth is, all the external services are overly general, but our case due to the nature of transactions is unique. We need an engine bent to our needs and our data, at least to address a certain subspace of problems. Such an engine would reap the benefits of our domain knowledge, labeled transactions and gathered entity data. Its cost and latency in principle should be more predictable and manageable. It is why it might be worth devoting some research time and engineering power to improve our entity-search performance even more.
So we’ve built an internal service around entities, which we can creatively call Entities Service. It comprises two interconnected components.
The first one is a store of our entity data, which is lovingly curated and contains not only organizations, but also frequently paid-for products. The service exposes endpoints to manually alter the data, which is often necessary to guarantee the correctness of the names and logos of especially important merchants.
The second is the search engine on top, which is guided by labels and domain knowledge. It stands on the hybrid index:
- purely text based index;
- vector embedding index.
The core flow of the applied search algorithm is typically boring:
- retrieval stage — high recall, simple and fast, but noisy;
- re-ranking and pruning stage — keep recall, while increasing MRR@k (k is small).
When crafting the text side of the index, we tried to incorporate any potentially useful field in multiple ways, e.g.:
- company names and aliases:- get rid of redundant llc, inc suffixes;- calculate phonemes (Soundex) to capture some fuzzy patterns, so that for instance, “Facebook” can be found for “Facbk”;
- market tickers, such as “AMZN”;
- website urls:- domains and subdomains undergo similar treatment to names;- form a path hierarchy, that is “subdomain.domain.com” should match with “domain.com” or “subdomain.domain”;
- addresses — fields like street, country, region, postcode, state, are copied to a single location field for partial matches when searching by LOCations.
This index is also strengthened with labeled data and domain-specific patterns. Consider a labeled transaction where part of the description, “dd”, corresponds to DoorDash. We add this substring to the indexed field labeled_terms: [“doord”, …] of the relevant document to boost its score the next time “dd” is searched for.
The text-based index quickly grew large and slow to update and query as we introduced n-grams or the limited fuzzy matching capabilities. On top of that, numerous patterns were difficult to catch with custom analyzers. This led us to offload the responsibility for brutally obfuscated names to a vector database.
Contrary to common applications of entity embeddings we do not aim at compressing any semantic meaning, which in fact would be detrimental to our efforts. When searching for a restaurant with “art” in its name we would like to avoid being flooded with museum locations. We simply want to perform fast and effective fuzzy matching, so Approximate Nearest Neighbor (ANN) deployed on properly extracted vector embeddings appears to be a reasonable approach. However, in our solution we don’t move far away from text-based search, at least not conceptually. Inspired by it, for each entity e in the database we create a list of m vectors [v₁ᵉ, …, vₘᵉ], where m depends on the entity in question. So we end up with separate vectors for different properties such as names, domains, or whole urls. We obtain them using models based on FastText and TF-IDF, which are trained on n-grams.
The idea of the vector-based retrieval can be displayed as follows:
- Receive a query c;
- Embed it using the same method as for entity fields to get vᶜ;
- Use ANN algorithm (e.g. HNSW) to get a set V of k nearest neighbors of vᶜ;
- Then the score for entity e is calculated as:score(e, c) = max{ σ(vᵢᵉ, vᶜ) ⋅ wᵢ, ₑ | vᵢᵉ ∈ V }where:- σ is a similarity measure,- wᵢ, ₑ is a weight assigned to i-th field of entity e, and can be tuned with Bayesian optimization with MRR as a target.
- Return a list of k′ (k′<k) top scoring entities.
Now we find ourselves with a fairly large set of entities which we have to slim down aggressively. Therefore, each entity passed from the two retrieval phases has its score recalculated as a combination of:
- a sub-score for text-based retrieval;
- a sub-score for vector-embedding retrieval;
- feature scores for e.g.:- entity “popularity measure”- location and market matching degree.
Only after that we are ready to output a few lucky entities (typically < 10).
Search Job Phase 2: Re-ranking, Resolution, Selection
We’ve just covered search engines that eagerly share with us a harvest of entity results. The path forward is clear — we have to assess their plausibility, resolve them into equivalence classes and throw away rotten seeds.
Responsibility for the first step rests on the shoulders of a cross-encoder model, which for a pair of requested query and the corresponding entity description yields a score in the range of [0, 1].
Note the model not only has to estimate the degree of potential matches. Above all, it is trained to be vigilant to tricky entity descriptions, especially in the case of web-search outputs.
The technical details of the training process are rather unimaginative, so we’ll eschew going through them. It is the data preparation part that determines the strength of this approach. Taking into consideration how hungry transformer models are, we cook our datasets in a semisynthetic way. We rely on the contents of our entities database, from which we sample a considerable portion of examples and obfuscate them in various different ways reminiscent of the degenerates which we encounter in everyday transactions.
>>> from entities.data.obfuscator import default >>> obf = default() >>> entity = Entity(name="Amazon Music", websites=["music.amazon.com"]) >>> obf(entity) ['Amazon Music', 'Amzon Mus', 'music . amazon . com', 'musc . amzn', ...]
Then having (query, website) pairs we reach out to all our search engines. The results with matching websites are marked as positive targets for the model, and the rest adds up to the set of negatives. Consequently, the cross-encoder also learns individual treatments towards specific search engines.
We arrive with our own scores for the whole list entities, which may contain elements representing the same real-world object. Our current solution for grouping them into families is somewhat naive, but safe.
(e₁, s₁), …, (eₙ, sₙ) → ((eᵢ, sᵢ), …)₁, …, ((eⱼ, sⱼ), …)ₖ
Matching different urls for the same entity together is troublesome, so we choose the simple approach of only matching domains. Here, like most of the time, we trade off recall for higher precision.
The task now is to move the inner entity sᵢ scores outside and have a single confidence score s’ᵢ for a whole group:
((e₁, s₁), (e₂, s₂), …)ᵢ → ((e₁, e₂, …), s’ᵢ)ᵢ
Afterwards, a group can be rejected when compared with a carefully tuned threshold value. To this end, we devised a formula that tries to include some intuitions:
- voting strength — increase confidence for larger groups;
- avoid ambiguity — decrease overall confidence if multiple groups have high scores;
- make use of our Domain Metadata database if possible — overwrite confidence based on rules.
Search Job Phase 3: Entity Enrichment and Representation Tuning
We’ve reached the last phase of the entity search job when we have key identifying information (websites, names, some ids) of the accepted entities. Being so information-thirsty, we consult with entity databases, as well as entity-search engines that have not previously given satisfying results, to further receive:
- tags
- alternative names
- logos
- descriptions
- addresses, e.g. by using detected store id “Spent Gigzter at LOVE’S #295” → “4564 W. 590, Chouteau, OK 74337, US”
- etc.
Arriving with a group of objects representing the same underlying entity, [eᵢ¹, …, eᵢᵏ], we tune the final representation, e’ᵢ:
- name is selected from the set of alternatives using a dedicated and relatively simple model;
- tags and descriptions are simple concatenations;
- Other attributes are chosen based on priorities of the corresponding sources.
Final Stage: Solution Selection and Role Classification
Finally, the entity search jobs are over leaving us with the last duty. We have to compile the end solution and assign each selected entity their transaction-specific role. So far the Pareto principle led us to a simple, but robust approach nonetheless:
- select only the top accepted entity for each candidate ORG;
- apply heuristics, pattern matching, and leverage labeled transactions.
Entities Search — System Architecture
But, before we conclude let’s have a bird’s eye view of the architecture to consolidate our thinking about the implemented entities search system.
The algorithm constituting the backbone of the search takes the central place in the diagram. It has two different modes of execution, real-time and batch, which differ in the way models are executed or how we estimate budgets for entity search jobs. You should take note of Triton Inference Server, which is a work-horse for running the cross-encoder.
Conclusion
This is the end of the journey through our entities search system, but we never stop in our efforts to elevate its performance and quality. An attentive reader could perhaps discern some gaps in the design, but also hopefully appreciate the decisions we’ve made so far. We also left out many details, which we spare for upcoming blog series.

